


This blog post is a high-level overview of how MapReduce works and how some of the concepts from my previous blog post on distributed systems can be seen applied in MapReduce.
What is MapReduce?
MapReduce is a computational model that was developed by Google to process large datasets. Since Google’s business model runs on indexing almost the entire data on the web, it needed a way to increase the efficiency of computation and have fault-tolerant ways of computation.
How does MapReduce work?
MapReduce runs on a large cluster of computers and the programs that run on it are parallelized [1]. MapReduce divides the computational resources into map workers and reduce workers.
From the user’s side, MapReduce is a library that allows the user to express the task as two functions - Map and Reduce. Each large task is broken down into smaller tasks that the map workers take up. Once the computation is completed, the reduce workers combine the results produced by the individual map workers to produce a meaningful output.
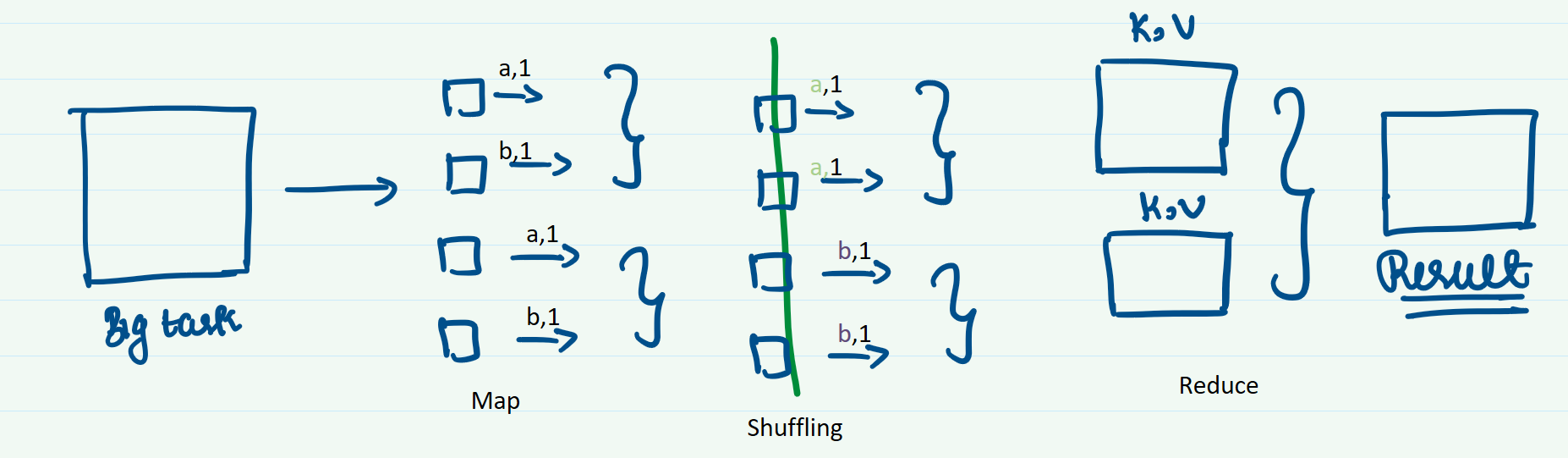
MapReduce also leverages the locality of data to overcome speed issues caused by network bandwidths. The cluster has input data stored within its local disks. MapReduce takes advantage of this fact by allocating map tasks to those computers within the clusters that have the input data so that a lot of data does not have to move across the network to be used for computation.
Since MapReduce was a system implemented in the early 2000s where network bandwidth was a big bottleneck, this implementation allowed large computations to occur fairly quickly without being throttled by network speeds.
How does MapReduce implement the basic characteristics of distributed systems?
Fault tolerance
MapReduce has a robust software and hardware fault tolerance mechanism. Workers are pinged regularly and if there is no response received from the worker then it is marked as failed. Any tasks that were being performed by a failed map worker are set to idle and are available for another map worker to be processed again. If the main program fails, a new copy of the task can be restarted from the previous checkpoint [1].
Scalability
MapReduce is a programming library and was extensively used at Google in the 2000s and 2010s. Since the user only had to represent a task in terms of its map and reduce functions, the user did not really need to have a deep understanding of distributed systems to successfully execute a task. Moreover, the library provided extensive coverage for fault tolerance and machine failure so that the programmer could focus more on optimizing the code instead. MapReduce has extensively helped Google in reducing its computation time and resources required for indexing webpages and reduced some of its issues related to network hiccups and machine failures